On February 1st, 2024, we released Nomic Embed - a truly open, auditable, and performant text embedding model. While the performance of an embedding model is often taken into consideration when evaluating it for production deployment, other factors including the memory, storage, and bandwidth requirements of the embeddings are also important to consider.
For example, storing the embeddings of a large dataset for a RAG app is often quite costly.
That's why we're excited to introduce Nomic Embed v1.5, which improves on Nomic Embed by giving developers the flexibility to explicitly trade off performance and embedding footprint.
Nomic Embed v1.5
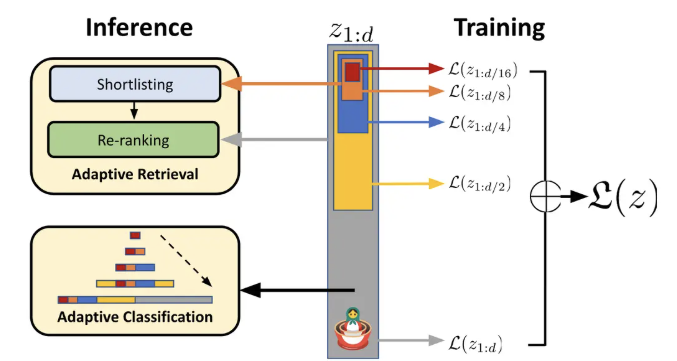
We train nomic-embed-text-v1.5 with Matryoshka Representation Learning to enable variable embedding dimensions in a single model.
Nomic Embed v1.5 supports any embedding dimension between 64 and 768 as well as binary embeddings.
Training and Evaluation
We finetuned nomic-embed-text-unsupervised on our nomic-embed-text finetuning dataset. You can replicate the model and openly access the data in the nomic-ai/constrastors repository.
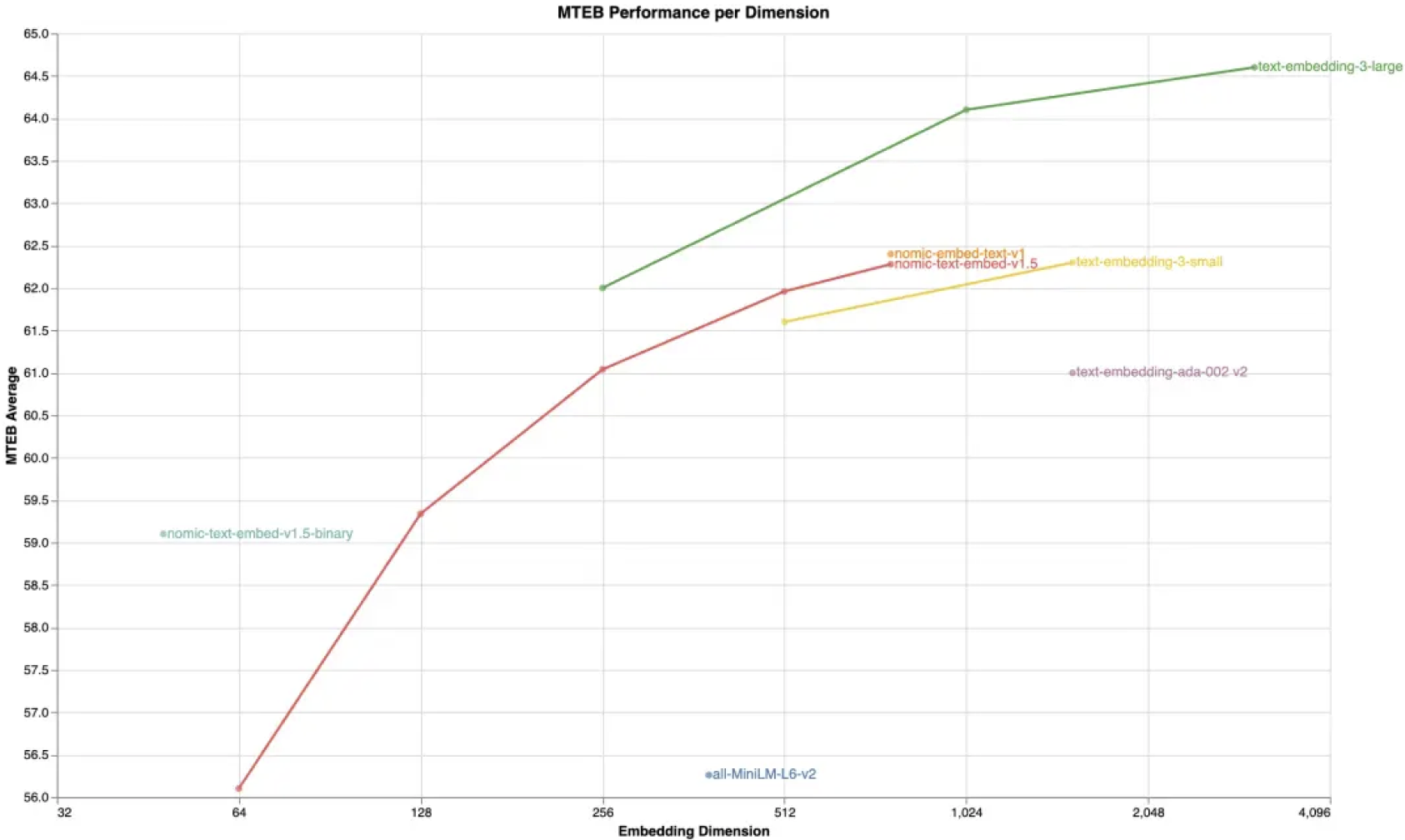
Nomic Embed v1.5 outperforms text-embedding-3-small at both 512 and 768 embedding dimensions.
At an embedding dimension of 512, we outperform text-embedding-ada-002 while achieving a 3x memory reduction. At a 12x memory reduction compared to nomic-embed-text-v1, our model performs similarly to all-MiniLM-L6-v2.
We found that our 768 dimensional performance is similar to nomic-embed-text-v1 while also enabling the variable degrees of freedom.
We did not evaluate text-embedding-3-small at lower dimensions because running the evaluation is prohibitively expensive and time-consuming as the model weights are not public.
You can explore the similarities and differences between different nomic-embed-text-v1.5 embedding dimensions using the custom mapping feature in the map below: