With the rise in AI code assistants like Cursor and Windsurf, effective code retrieval is critical for improving code generation across large codebases. Existing code embedding models tend to struggle with real-world challenges like finding bugs in Github repositories, likely due to noisy inconsistent data used during training.
As an extension to our ICLR 2025 paper CoRNStack: High-Quality Contrastive Data for Better Code Retrieval and Reranking, we've scaled up and trained Nomic Embed Code, a 7B parameter code embedding model which outperforms Voyage Code 3 and OpenAI Embed 3 Large on CodeSearchNet. Like all of Nomic's models, Nomic Embed Code is truly open source. The training data, code, and model weights are all available on Huggingface and Github under an Apache-2.0 license.
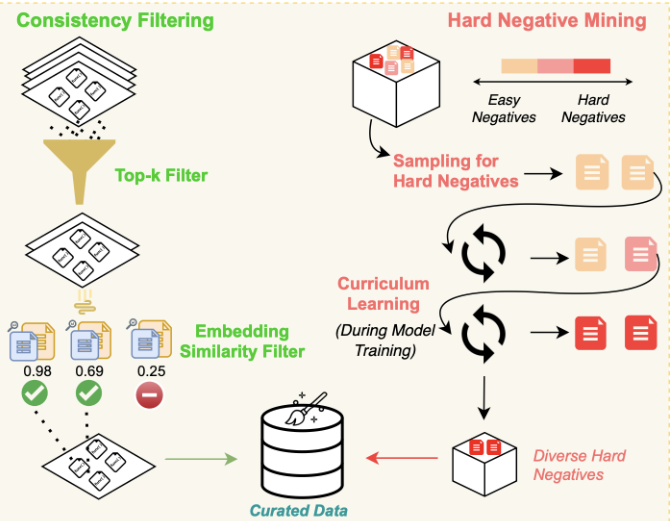
The CoRNStack
CoRNStack, is a large-scale high-quality training dataset specifically curated for code retrieval. The dataset is filtered using dual-consistency filtering and utilizes a novel sampling technique to progressively introduce harder negative examples during training.
In CoRNStack, we trained and released Nomic CodeRankEmbed, a 137M parameter code embedding model, and Nomic CodeRankLLM, a 7B parameter code reranking model. Now, we've unified the retrieval and reranking models into a streamlined 7B parameter model, Nomic Embed Code.
Nomic Embed Code
Nomic Embed Code is a 7B parameter code embedding model that achieves state-of-the-art performance on CodeSearchNet.

Like our previous models, Nomic Embed Code is truly open source. The training data, code, and model weights are all available on Huggingface and Github.