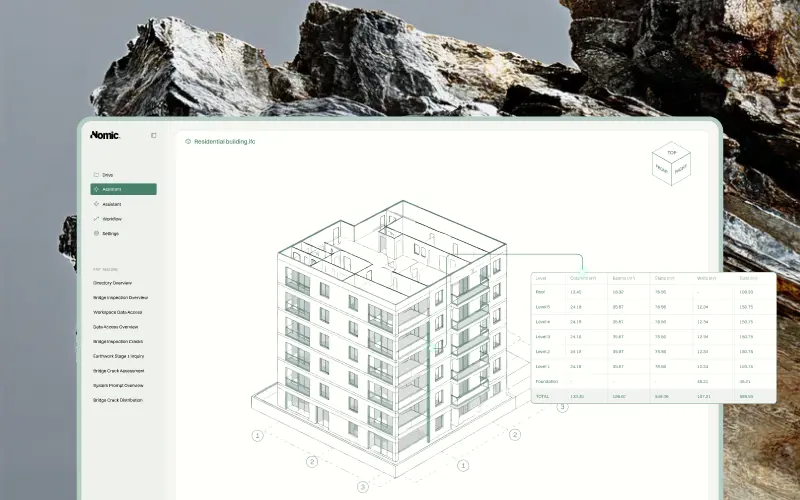
Construction projects generate a staggering volume and variety of documents. A single commercial building project might produce thousands of drawing sheets, hundreds of specification sections, dozens of submittals, and a continuous stream of RFIs, meeting minutes, and field reports. These documents span a range of formats — from dense technical drawings to structured text specifications to photographs and scans.
For AI to be useful in this environment, it needs to work across all of these modalities. A system that only understands text will miss the critical information embedded in drawings. A system that only processes images will lose the context provided by specifications and code requirements. The challenge — and the opportunity — is building AI that can reason across the full multimodal landscape of construction data.
Why Text-Only AI Falls Short
The most common approach to applying AI in document-heavy workflows is text extraction followed by language model processing. For many industries, this works well enough. Legal contracts, financial reports, and medical records are primarily text documents where OCR and NLP can capture most of the information.
Construction documents are different. A structural drawing communicates information through a combination of lines, symbols, dimensions, annotations, and spatial relationships that text extraction cannot fully capture. The relationship between a beam and a column is conveyed by their geometric position on the drawing, not by a text description. A keynote callout references a material specification, but the spatial context — where on the building that material is used — is conveyed visually.
Standard OCR extracts text from drawings but loses the spatial relationships that give that text meaning. A dimension string "12'-0"" extracted from a drawing is meaningless without knowing what it dimensions. An annotation "TYP" (typical) only makes sense in the context of the elements it modifies.
The Multimodal Approach
Multimodal AI processes text and visual information together, maintaining the relationships between them. For construction documents, this means:
Drawing understanding. Instead of treating drawings as images to be OCR'd, multimodal models can understand the visual language of construction documents — recognizing symbols, parsing annotations in context, and understanding the spatial relationships between building elements.
Cross-document reasoning. A specification section references drawing details. A drawing references other drawings. Multimodal AI can follow these references across document types, maintaining context as it moves between text and visual information.
Visual search. Engineers and designers often think visually — they are looking for a specific type of detail or a particular construction condition. Multimodal embeddings enable search that works across text queries and visual content, finding relevant drawing details even when they are not described in text.
Technical Foundations
Building effective multimodal AI for construction requires advances at multiple levels of the technology stack:
Parsing. Construction drawings are high-resolution, symbol-dense documents that require specialized parsing. Standard document AI models trained on business documents or web content lack the training data to handle the visual vocabulary of AEC — section markers, door swings, structural grids, elevation markers, and hundreds of other symbols.
Embeddings. Creating meaningful vector representations of multimodal construction content requires embedding models trained on AEC data. At Nomic, our embedding models are trained to understand the relationships between text, images, and construction-specific visual content, enabling semantic search across all document types.
Retrieval. Retrieval-augmented generation for AEC must handle queries that span modalities — a text question that should return a drawing detail, or a visual query that should return a specification section. This requires a unified embedding space where text and visual content can be compared meaningfully.
Real-World Applications
Multimodal AI enables practical workflows that were previously impossible:
A project manager asks "Show me all fire-rated wall details in the current drawing set" and gets visual results from across hundreds of sheets. A code reviewer checks a drawing against building code requirements that reference both text provisions and illustrative figures. A contractor searches across project documents — drawings, specs, and submittals — to find all information related to a specific building system.
These are not hypothetical use cases. They are the workflows that our customers use daily on the Nomic Platform.
The future of AI in AEC is multimodal. The question is whether your tools are ready for it.